コピー機のOCRでDX推進。紙資料のデータ化で検索が捗る!

紙資料からテキストデータ化したい場合や、必要な文献や資料が紙媒体でしかない場合、一文字一文字パソコンに打ち込んで書類を作成する作業は時間が奪われます。また、データではないため検索ができず、膨大にかさばる紙資料の中から、目的の資料を見つけ出すことも一苦労です。そしてあなたが作業中の業務もストップして支障をきたしてしまいます。そのような時に役立つ機能、それがOCRです。この機能があれば煩わしい文字起こし作業も大幅に簡素化され、検索機能で資料探しも瞬時に解決です。
一昔前はOCRの認識精度が低かったため、「当時は全く使い物にならなかった」という経験からのご意見がある方もいらっしゃるかもしれません。しかし、現在のOCR機能は打って変わり超絶進化しています。今回は、技術の進化により認識精度が向上したOCRの仕組みと、各メーカーのOCR機能をご紹介いたします。
OCRとは
OCRとはOptical Character Reader(またはRecognition)の略です。紙媒体のテキスト部分をOCRが搭載されたイメージスキャナや複合機が認識し、文字データに変換する光学文字認識機能のことです。
一昔前までのOCR技術はいまひとつ正確ではなく、しかも日本語にはひらがな、カタカナ、漢字と表現が複数あるため、認識が難しく、誤字や意味の伝わらない言葉になることが多々ありました。しかし、現在ではOCRにAI(人工知能)を組み合わせてスキャンと解析を繰り返す技術により、認識率が飛躍的に向上しています。
紙媒体から文字を認識して抽出する流れ
では、OCRはどのように画像を解析して文字データに変換するのでしょうか。実はOCR機能は、私たち人間と同じように少しずつ文字を認識しているのです。OCRが認識する仕組みと流れを解説いたします。
① 元データから画像解析
まずはスキャンで読み取った書類の画像を解析します。ここで行う解析は、書類のレイアウトの中に、文章の部分と画像の部分を区別することです。以前は手動で文字の範囲を設定していたこともありましたが、近年のOCR機能はほぼ自動で文字範囲を認識しています。

文字の部分と画像の部分を識別します。
② 文字領域を切り出し解析
文字範囲に文字列が何行あるのか、一行はどこの部分なのかということを解析します。一文ではなく一行のため、文が途中で区切られます。例えば、8文あり10行の文章の場合でも、10行を四角で区切るように切り出しを行っています。

一文ではなく、一行での解析を行います。
③ 行内の文字を解析
一行ごとに切り出した文章を、その一行に含まれている文字を一文字ずつ分解して解析します。文字に沿って認識するための線が移動し、文字の形を認識していきます。この線は数値として表され、この数値が「0」の場合は文字と文字の区切りとして判断されるのです。このため原稿の間隔が狭い場合や、手書きの文章は文字を切り出すことが難しいと言われています。

文字は一文字一文字、バーを動かして解析しています。
④ 解析された文字を認識
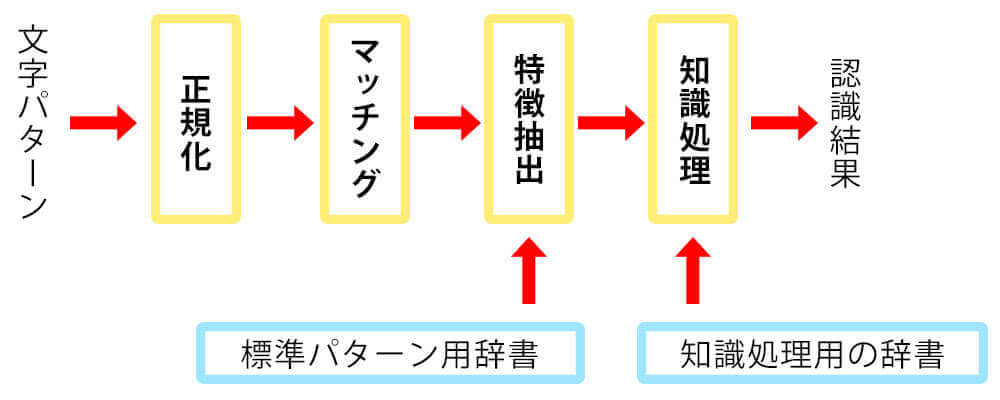
行から分解された文字を、一文字一文字認識していきます。正規化、特徴抽出、マッチング(標準用の辞書)、知識処理(知識処理用の辞書)の工程により文字を認識しています。文字の大きさや書体、潰れや掠れなどの文書によって違うパターンを調整しているのです。
⑤ 認識した文字を訂正
文字を認識した結果をAIや辞書データベースより、前後や全体の文章を把握し適正な文字かどうかを判断して訂正していきます。ここでの文字訂正処理は日々進化をしており認識率が向上しています。
⑥ テキストに変換
認識したデータを処理し、テキストデータへ変換します。OCRの機能によってはPDF、Word、Excel、HTMLなどのフォーマットに変換して出力できるものもあります。このフォーマット変換機能により、元の原稿とほぼ同じレイアウトのデータ原稿が完成するのです。
OCRで認識しにくい文字
前述のようにOCRは、文章を行に、行を文字に分解し、一つ一つ解析しています。このように細かく認識しようとしても、100%正確に文章を認識することはできません。
- カラー文字
- 掠れた文字
- 網掛けされている文字
- 原稿が斜め
- 文字同士の間隔が狭い
- 小さい文字
- ミミズの這ったような汚い字
- 機種依存文字(※)
上記がOCR機能で認識しにくい文字です。具体的に認識しにくい文字の例として、「1(いち)」と「I(アイ)」や「l(エル)」や「0(ゼロ)」と「O(オー)」などがあります。また、漢字の「一(いち)」や「二(に)」、ひらがなの「の」や「ぬ」や「め」なども認識しにくいそうです。しかしそのような文字はAIの力で文章の前後を読みとることにより、改善されつつあります。
※機種依存文字とは、電子的に扱う文字データのうち、処理系によって違う文字に表示されたり、全く表示印刷できなかったりする文字のことです。
大手メーカー3社のOCR機能の紹介・やり方
SHARP
シャープの複合機にはシンプルモードが搭載されており、よく使う機能を表示し、複雑な操作を無くしたものになります。このシンプルモードは標準機能で搭載されているのですが、シンプルモードの機能の中にOCR機能があるのです。(MX-3661 / MX-3161 / MX-2661限定)
シンプルモードなので、OCRの操作もシンプルです。
- まずは紙文書をスキャンします。
- シンプルスキャンをタッチします。
- 本体・デバイスに保存をタッチします。
- 本体に保存するか、デバイスに保存するか選択します。
- 「フォーマット」を選択し、OCR文字認識にチェックを入れるとOCR解析が開始します。
「フォーマット」から保存したいファイルの拡張子を選択可能です。拡張子の種類は、PDF、PDF/A-1a、PDF/A-1b、TXT(UFT-8)、RTF、DOCX、XLSL、PPTXなど複数から選択が可能です。
OCR機能、シンプルモードの詳細はこちらの記事をご覧ください!

Canon
キヤノンの複合機にはOCR機能は搭載されていません。スキャンソリューション機能拡張キットというオプションの中に、OCR機能が含まれています。
- 原稿をセットします。
- 「スキャンして送信」を押します。
- スキャンの基本画面で宛先を指定します。
- 必要に応じて読み込み設定をします。(ファイル形式を選択する、解像度を選ぶ、原稿の読み取りサイズを設定するなど)
- ファイルを選択します。複数ページの原稿をページごとに分割して、別々のファイルとして送信する時は、<ページごとに分割>を押して、分割するページ数を入力。
- 「OK」を押すとOCR解析が開始します。
ファイルの選択種種類は、PDF、XPS、OOXML(Word、PowerPoint)などがあります。OCRの「原稿向き自動検知」がONの場合、ファイル形式で「PDF」、「XPS」、「OOXML」を選択すると原稿の向きを検知して、自動的に送信されます。また、OOXMLからWordを選択した場合、読み込んだ背景画像の消去が可能です。不必要な画像が消えるため、Wordファイルの編集がしやすくなります。オプションのため無料ではありませんが、30カ国以上の言語にも対応が可能のため便利に活用ができます。
FUJIFILM
紙文書から作成したDocuWorks文書がテキストデータに変換されます。
スキャン取り込みタブでOCR処理を設定します。OCR読み取り後に自動的に行うように設定ができます。
- ディスクメニューのファイル「DocuWorksの設定」を押します。
- 環境設定ダイアログボックスが表示されます。
- 設定画面内のスキャン文書の後処理内にあるスキャン文書に、「スキャン後にOCR(文字認識)の処理をする」のチェックボックスにチェックを入れます。
- 「OK」をクリックするとOCRが開始します。
「スキャン取り込み」タブの「スキャン文書の後処理」では、「スキャン後にOCR(文字認識)の処理をする」の他に、「読める方向に全ページを自動回転する」を選択することができます。この設定を行うと、スキャンで取り込んだ文書の向きが横向きや逆向きになることはなく、自動的に向きを補正して表示されます。
OCRは紙文書に印刷された文字を認識し、テキストデータに変換する技術です。いつも通りスキャンした紙文書は文字のデータにはならず、単なる画像として保存されます。しかし、OCRを使用することでテキストデータ化されるのです。OCRはペーパーレス化に対して重要な「何が書いてあるのか」というポイントを解決してくれますし、ペーパーレス化が促進されることによって、DX(デジタルトランスフォーメーション)も進みます。編集データを紛失してしまった紙文書や、手書きの文書、文が書いてあるが画像のままのデータなど、紙文書が溜まってきて整理が難しいと思っている方は、積極的にOCRを活用されてみてはいかがでしょうか?




この記事の監修者

株式会社庚伸 『事務機器ねっと』 オフィスサポートディビジョン
フィールドエンジニアグループ |
シニアマネージャー
大塚 義美
複合機メンテナンス許可認定
FUJIFILM/Canon/SHARP/EPSON
経歴
複合機のメンテナンスエンジニアとして業界歴26年以上のキャリアから、フィールドエンジニアグループのマネージャーとして事業部を統括。凡そ4万5,000回以上の複合機メンテナンス実績があり、コピー機やプリンターを隅々まで熟知。お客様が抱えられている課題やお悩みに対して真摯に向き合ってサポートすることがモットー。これまでに培った多くの知見と経験を活かした有益な情報を発信いたしますので、少しでもお役立ていただけると幸いです。
最新の記事



“プロの目利き”で、最適なコピー機選びをご支援。





人気コピー機ランキング



いま読まれている人気記事












 事務機器ねっとは「コピー機・プリンターリース価格満足度 第1位」と「コピー機・プリンター販売サイト導入後のサポート満足度 第1位」の二冠を獲得しました。
事務機器ねっとは「コピー機・プリンターリース価格満足度 第1位」と「コピー機・プリンター販売サイト導入後のサポート満足度 第1位」の二冠を獲得しました。
 第37号‐24020002
第37号‐24020002JIS Q 27001:2023(ISO/IEC 27001:2022)
 (適用範囲:HCグループ)
(適用範囲:HCグループ)
一般人材派遣業:労働大臣許可 派13-01-0526
人材紹介業:労働大臣許可 13-ュ-010435
宅地建物取引業:東京都知事(3)第98397号
一般建設業:東京都知事許可(般-1)第150856号
高度管理医療機器等販売/貸与業第5502205165号
 人数無制限・定額制の勤怠管理システム
人数無制限・定額制の勤怠管理システム 現場がイキイキと自走するRPA導入支援
現場がイキイキと自走するRPA導入支援 現場の声に応えるオーダーメイド型BPO
現場の声に応えるオーダーメイド型BPO